C07 - A registered report on German demonstrative pronouns
Clare Patterson
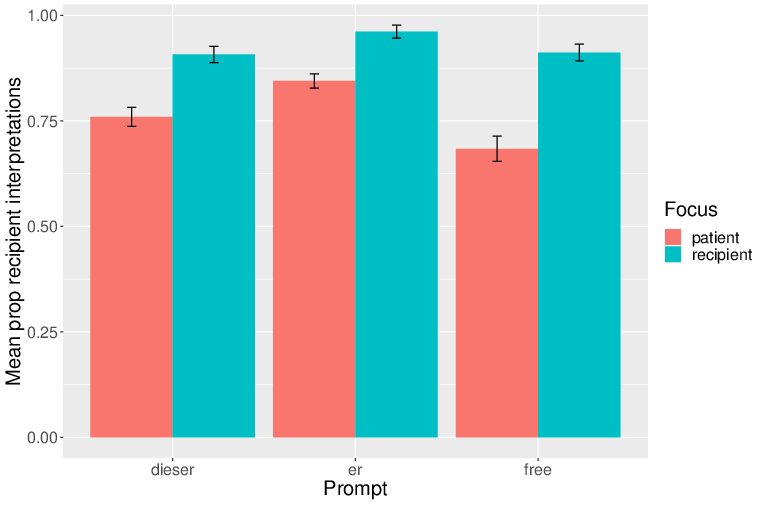
In project C07 we wanted to investigate the influence of focus on the resolution of German demonstrative pronouns. Focus makes an entity more salient and likely to be referred to again (e.g. with a pronoun) in subsequent discourse. There is plenty of evidence that focus affects personal pronouns; pronouns are more likely to refer to an entity that is in focus. But the effect of focus on demonstratives presents a puzzle with respect to prominence, since German demonstratives tend to refer to less prominent entities (prominence avoidance). Our question was, would demonstratives also be sensitive to focus just as personal pronouns are, or would focus push resolution preferences in the opposite direction for demonstratives because of prominence avoidance?
We had a clear research question and an established experimental method, so we thought that this project would be an ideal candidate to submit as a registered report.
Why a registered report?
Registered reports (RR) are an important tool in the open science toolkit. They are a type of paper in which the introduction, methods and hypotheses are evaluated by reviewers before the data has been collected. Data collection can begin only once the stage 1 paper has been approved. After data collection, a full version of the paper (including results) is submitted, but no changes to the pre-approved design or hypotheses are permitted. The advantages of this approach are more rigorous study planning and reduced opportunity for HARKing (hypothesizing after results are known), which increases reliability of results.
In C07 we had already been pre-registering our predictions for experiments (e.g. https://aspredicted.org/dt6ny.pdf), but this project was our first attempt at RR. Compared to a ‘normal’ experiment, more time is required up-front because data collection is delayed, and because a first draft of the paper (excluding results) has to be written, reviewed and revised. However, writing up the results and getting reviewer approval for the full paper was quicker than normal, because any issues with the design or theoretical approached had already been resolved at stage 1.
Challenges: power analysis and design complexity
One challenge we faced when preparing the RR was estimating power. The journal (https://online.ucpress.edu/collabra) required a very detailed power analysis for stage 1 (this is a standard requirement for RRs), with the requirement of minimum a priori power of 0.9 for every effect we wanted to test. We had 5 effects per experiment to calculate because of the rather complex experiment design. Our method for power analysis (power simulation) works best when it is based on previous similar experiments with known effect sizes, but these did not exist in our case; we therefore had to simulate based on a combination of pilot data and previous data with a similar experimental method but a different research question.
A further challenge was that the complex design of our experiments made it harder to foresee the possibilities for interpretation in advance of seeing the results, but an interpretation plan is an essential component of the stage 1 manuscript. For anyone interested in submitting an RR, I would suggest starting with a single, simple experiment with a small number of effects!
Data accessibility
The journal required that the stage 1 approved manuscript be time-stamped archived (https://osf.io/auvmz). They also required code, data and experimental materials to be archived in a public repository. We chose to use OSF for this (https://osf.io/a3dsm/). We had to ensure participant anonymity which we did by stripping the Prolific ID number from the data before posting it (the participant names were never part of the data frame).
What we learned
Publishing an RR was a steep learning curve but an overall a positive experience; I would like to move towards publishing in this way as standard. Reaching the 0.9 power requirement meant having to test more participants than we would normally, but it gave us confidence that we were less likely to miss a small effect due to lack of power. This has made us reflect more critically about issues of power in other experiments. We benefited hugely from the R package mixedpower (Kumle & Draschkow, 2020) and the accompanying tutorial (Kumle et al. 2021). At the same time, I would appreciate more discussion in the field of psycholinguistics about applying power simulation in situations where there are few or no existing studies to draw on.
The RR process at Collabra: Psychology is particularly well managed and author-oriented. I would appreciate more journals making RR available, and more discussion in our sub-field about the challenges of the rigorous study planning that is required for RR.
References
Kumle, Leah & Dejan Draschkow. 2020. DejanDraschkow/mixedpower: The Force Awakens (v2.0). Zenodo.
Kumle, Levi, Võ, Melissa L.-H. & Dejan Draschkow. 2021. Estimating power in (generalized) linear mixed models: An open introduction and tutorial in R. Behavior Research Methods 53(6). 2528–2543.
Patterson, Clare, & Petra B. Schumacher. 2023. How focus and position affect the interpretation of demonstrative pronouns. Collabra: Psychology 9(1): 75350.