C03 - The development of postverbal subjects in L2 Italian: A multifactorial corpus analysis
Andrea Listanti
We analysed the production of verb-subject structures in Italian by non-native speakers (adult L2 learners). Our aim was to investigate how the syntactic, semantic and pragmatic features associated with these constructions change across the different proficiency levels of the learners who produce them. To do so, we made use of the biggest learner corpus in Italian: the L.I.P.S. (Lessico Italiano Parlato da Stranieri) corpus. The corpus is entirely open access and publicly available at https://parlaritaliano.studiumdipsum.it/it/653-corpus-lips. It contains orthographic transcriptions of oral texts produced by Italian students during the exam for the certification of Italian as a foreign language. It encompasses 1420 transcripts, corresponding to 100 hours of recorded speech. The proficiency level of the students (from A1 to C2) is reported in the metadata. The data included in the corpus have been collected between 1993 and 2006. Our study has considered data from 2002 and 2003.
Data annotation and analysis
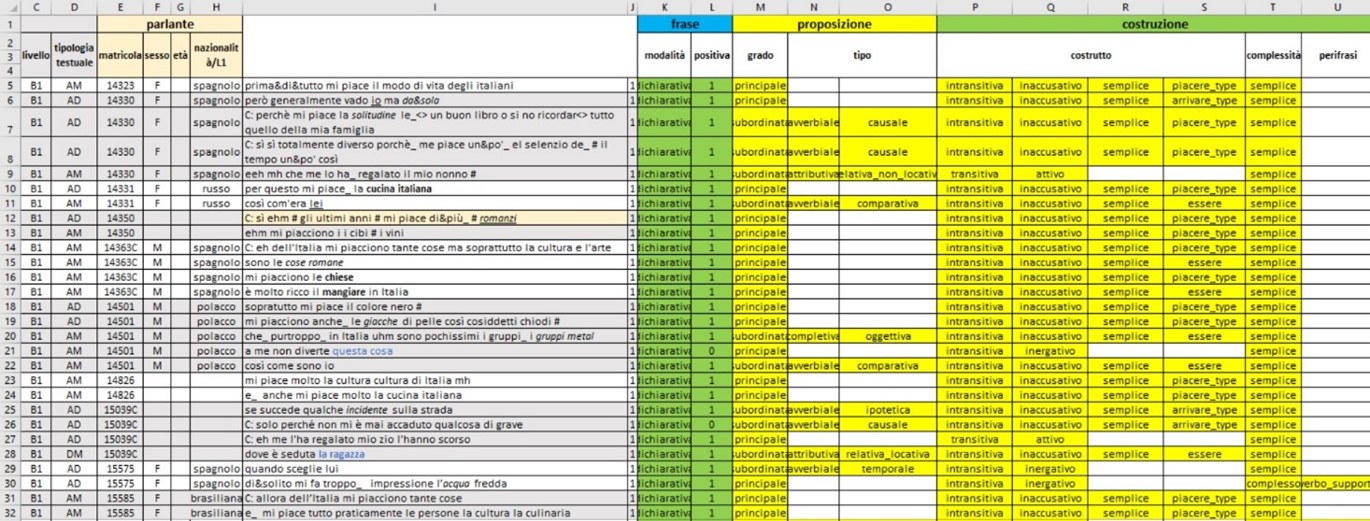
We divided the transcriptions into units, based on the occurrence of a finite verb. In our terms, a “unit” is a sentence produced by a learner, in which the subject can be either preverbal or postverbal (or null). For our analysis, we only considered instances of postverbal subjects (VS structures). We collected 653 VSs in total. We coded all these units for a set of linguistic features related to the verb and the subject constituent. We selected the following features:
- Verb class
- Dynamicity of the verb
- Frequency of the verb in Italian
- Information status of the subject
- Subject-verb agreement errors
- Agentivity of the subject
- Occurrence of other constituents in addition to verb and subject
- Clause type
- Syntactic complexity of the subject
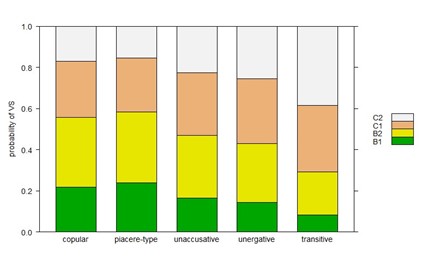
These features were included in a cumulative link mixed model as independent variables. As a ordered dependent variable, we selected the four proficiency levels considered in the study (B1 < B2 < C1 < C2). The statistical analysis has been performed using the open access software R. The results indicate learners’ progressive mastery of the mechanisms of assignment of the subject function to the postverbal constituent and increasing sensitivity to contrastive focus as a relevant feature for the use of verb-subject order.
Data accessibility
To guarantee the reproducibility or our study, the full dataset and the analysis script have been stored in the Open Science Framework website and are now publicly available to download. The public availability of the data through an online open science repository was one of the requirements we needed to meet in order to publish the study in the journal Applied Psycholinguistics. The paper has been recently accepted for publication (Listanti & Torregrossa, 2024). Thanks to the financial support provided by the SFB, the article and its supplementary materials (with additional examples of annotation and an alternative statistical analysis) will be published in open access. Upon request, we also provide additional annotation materials (such as the excel annotation files of every single transcription) to colleagues and students who may be interested in the study.