A06 - General issues with sharing audio data
Heiko Seeliger
Anonymity
Prosodic data in its raw form – voice recordings, or possibly even video recordings – is inherently identifiable. In A06, we give participants of our production studies a wide range of options of what we can do with their data. For sharing, they can opt in or out of sharing (i) with other researchers within the University of Cologne, (ii) with other researchers at non-commercial research institutions within the EU, and (iii) such researchers outside of the EU. As regards playback of the recordings, they can opt in or out of:
- Any kind of publication
- Online appendices connected to publications
- Talks
- Use in follow-up studies as stimuli
- Teaching (i.e. playback in seminars)
- University websites
- None of the above
The playback options explicitly relate only to the actual voice recordings, while the sharing options relate to any kind of data. This raises a potentially thorny issue: Audio recordings of someone speaking are clearly personally identifiable (i.e. if I know the person speaking, I will recognize them by their voice); aggregated data, on the other hand, is usually treated in the field as clearly not personally identifiable. By ‘aggregation’, I mean any kind of dimensionality reduction, such as e.g. calculating mean F0 per syllable/word/utterance/etc. The potential issue is where to draw the line.
For example: Are F0 contours personally identifiable? Absent information about formants (at the very least), it is not possible to reconstruct someone’s voice from such data, but there are surely cases where it would be possible to recognize someone from the playback of an F0 contour. This type of data is generally treated as not personally identifiable, but in my opinion, this is an edge case. Aggregated formant data is another example: Often, it is the very point of research on formants to identify speaker-specific variations in vowel quality. Nevertheless, formant data is generally treated as anonymous enough.
Amount of data & file sizes
There is at least one more reason, besides anonymity, why audio recordings are not generally widely shared: WAV files are fairly large (roughly 5 MB for a one-minute recording sampled at the standard 44.1 kHz and 16 bit sampling depth). Compression is usually ‘lossy’ – i.e. it changes the signal, which is undesirable in research – but even a lossless compression format such as FLAC still weighs in at around 2 MB for a one-minute recording. As a consequence, corpora of audio recordings, particularly large ones, are usually only shared on request, if at all.
Researcher degrees of freedom
A challenge that is not at first sight related to the concept of open science is that of researcher degrees of freedom (see Roettger, 2019, for much more detail). In my experience, this challenge is particularly great in research on prosody, because there are virtually always multiple different ways of quantifying a phenomenon of interest, and there is rarely, if ever, one correct option.
As a deceptively simple example, take the concept of duration. The duration of e.g. a syllable or word has a clear definition (if we ignore the issue of unclear segment boundaries resulting from co-articulation and reduction processes, which are very common), but at least the following questions arise in research on duration:
- Should duration be measured in ‘raw’ milliseconds, or should it be log-transformed? (Syllable and word durations tend to follow a log-normal distribution, so there is a comparatively large degree of agreement on this point.)
- Should duration be measured on an absolute or a relative scale, e.g. by calculating how much time a syllable/word takes up in an utterance proportionally. The latter option could potentially correct for overall differences in speaking rate.
- If a relative scale is used, the resulting measure will usually be bounded by (0, 1). In that case, linear (mixed) models can theoretically yield nonsensical estimates, and some form of generalized linear (mixed) model (e.g. a model assuming an underlying Beta distribution) would be more appropriate.
This issue relates back to open science in two ways. First, it is particularly important in prosodic research to be transparent about the analyses that were tried and the analyses that weren’t. Second, most of the problems posed by the multidimensionality of prosodic data can be circumvented by making the data available. As an example, even if it is transparently reported that only log-transformed absolute duration was analyzed, interested researchers can try alternative analyses if the data are available.
The specific case of A06
The production data recorded in the scope of A06 has differing availability (see above). The data analysis pipeline is entirely open source: We use Praat for annotation and the initial steps of data analysis, and R for more advanced data transformation, visualization and statistical analysis. Praat and R can interface fairly well using the R package rPraat (Bořil & Skarnitzl, 2016). There is also a Python implementation of (most of) Praat’s functionality (Jadoul, Thompson & de Boer, 2018).
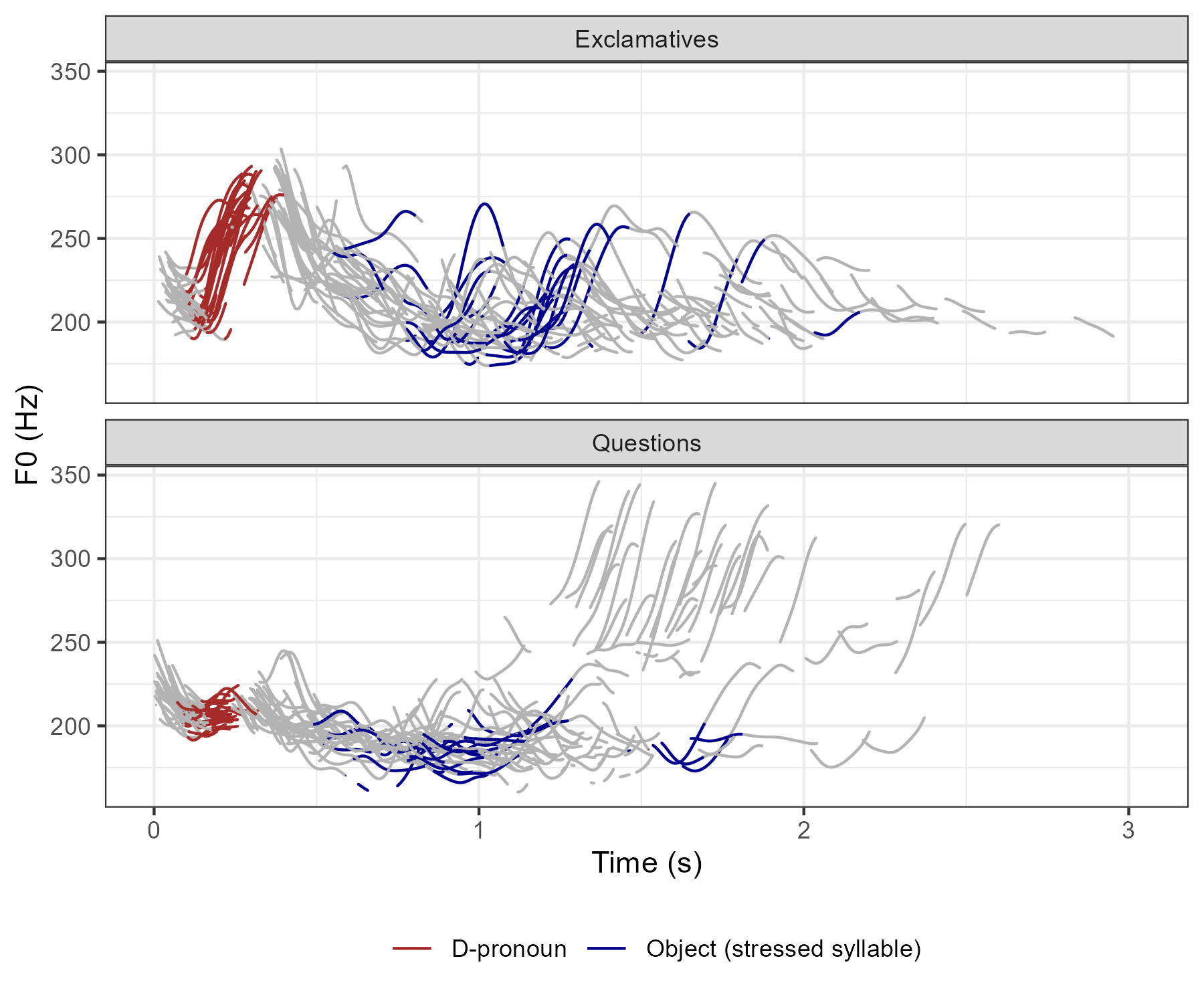
The core data types collected by us are audio recordings in WAV format (the ability to be shared depends on each individual participant, as noted above), Praat textgrids, i.e. annotation files with information about syllable boundaries and accent locations (generally sharable) and Praat pitch files, i.e. text files containing information about F0 contours (generally sharable with the potential caveat about anonymity noted above).
An example of how this type of data can be visualized is shown in the figure below. Shown are F0 contours from one participant of a production study investigating two German sentence types (exclamatives and questions). Without going into any detail, this figure shows that exclamatives and questions differ in their boundary tones (low vs. high), that exclamatives contain many prominent early accents while questions do not (highlighted in red), and that exclamatives tend to be longer than questions.
References
Bořil, Tomáš & Radek Skarnitzl. 2016. Tools rPraat and mPraat. In Petr Sojka, Aleš Horák, Ivan Kopeček & Karel Pala (eds.), Text, Speech, and Dialogue, 367-374. Springer International Publishing.
Jadoul, Yannick, Bill Thompson & Bart de Boer. 2018. Introducing Parselmouth: A Python interface to Praat. Journal of Phonetics 71. 1-15.
Roettger, Timo. 2019. Researcher degrees of freedom in phonetic research. Laboratory Phonology 10(1). 1.