A03 - Contour clustering: A novel approach to intonation analysis
Constantijn Kaland
Constantijn Kaland introduces an innovative, data-driven approach to describe prototypical intonation patterns. This method is especially beneficial for the early stages of prosodic research and offers several advantages over conventional techniques. Notably, it can be applied to spontaneous speech, is language- and domain-independent, and has the potential to uncover the multifaceted functions of intonation. Such capabilities make this approach invaluable for language documentation, an area where prosodic descriptions are often absent.
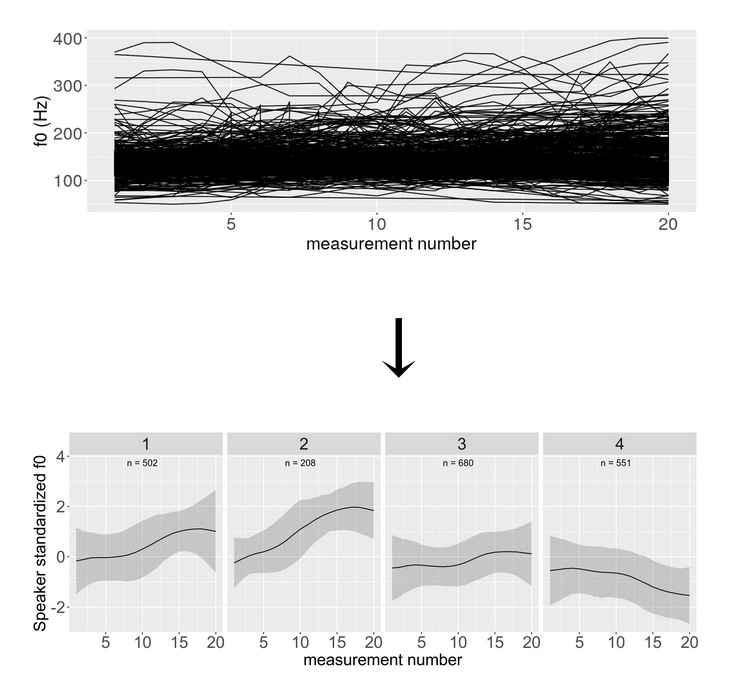
Central to this method is a cluster analysis performed on a time-series of f0 measurements. To this end, a Shiny app is available via this link. It offers a graphical user interface to perform f0 measures and cluster analysis entirely in R (Studio). Alternatively, a Praat script is available for the f0 measures. Researchers can analyze a wide spectrum of speech data, from spontaneous conversations to highly controlled scenarios. The process minimizes the need for manual annotation and can account for speaker variability. As for data, the tool works with .wav/.mp3 and Praat TextGrids as input. The output are dataframes with clusters annotated to the original textgrid data, and graphs/tables summarizing them.
In essence, the contour clustering approach offers a fresh perspective on intonation analysis. By focusing on the acoustic form of the intonation contour and leveraging reproducible data analyses, it paves the way for more objective, linguistically inclusive and comprehensive studies prosody and intonation. All necessary materials, including scripts and datasets, are readily available online, ensuring that the research community can benefit from and build upon this groundbreaking work. To date more than 20 languages have been analysed using this approach.